The Setup
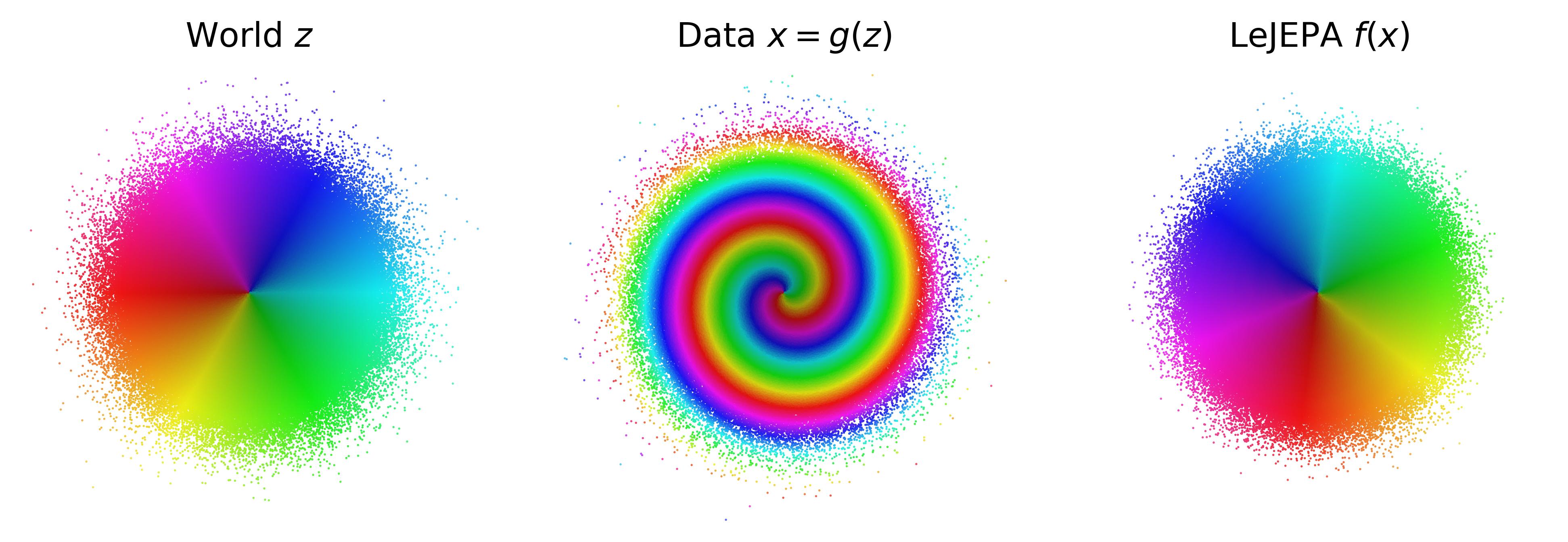
(left) The world has independent Gaussian latent variables. (center) An unknown nonlinear process scrambles them into the data we observe. (right) LeJEPA recovers the latent variables up to rotation. We prove this is the unique optimum.
The world. Latent variables $z \in \R^n$ with independent components and a stationary, additive-noise transition $z' = m(z) + \eta$. The world is observed through an unknown nonlinear mixing $x = g(z)$.
The learner. LeJEPA trains an encoder $h$ to minimize alignment between positive pairs $(z, z')$ subject to a Gaussianity constraint on its embedding distribution:
$$\min_h\ \E\!\left[\,\|h(z') - h(z)\|^2\,\right] \quad \text{s.t.} \quad h(z) \sim \N(0, I_n).$$
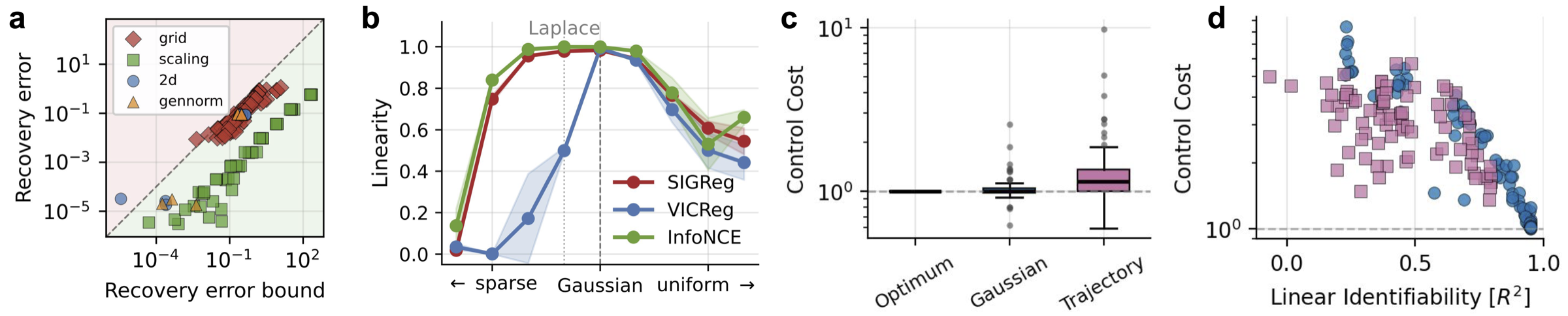
The Gaussianity constraint is enforced in practice by the Sketched Isotropic Gaussian Regularizer (SIGReg).